NWT: Towards natural audio-to-video generation
with representation learning
29 minute read
Preprint: arXiv
VQ-VAE1 shows that free-form video generation is possible, we extend these findings to show that we can condition such a video generator on external inputs
Overview
Results
All generated clips shown are model outputs with no post-processing or special tricks. None of these were seen by the model during training time.
Random samples
Episode Control
Audio-to-Video
| ol-1ZAPwfrtAFY | ol-DnpO_RTSNmQ | ol-hkZir1L7fSY | ol-Ylomy1Aw9Hk |
Video-to-video
| ol--YkLPxQp_y0 | ol-0UjpmT5noto | ol-eAFnby2184o | ol-nh0ac5HUpDU |
Mid-sample quick change
Style control
Single dimension control
Vertical Camera Angle: Up -> Down
Horizontal Camera Angle: Left -> Right
Camera Zoom: Zoom -> Unzoom
Combination: Top Left zoom -> Bottom right unzoom
Copy style from reference
In the next samples, the first row shows the videos used as source to copy the style from.
Random style sampling
Ground truth comparisons
| Inference 1 | Inference 2 | Ground Truth |
Video compression and reconstruction
We put the compression rate relative to uncompressed data in parentheses.
| Ground Truth (1x) | H.264 (200.1x) | NWT (396.1x) | NWT (803.2x) |
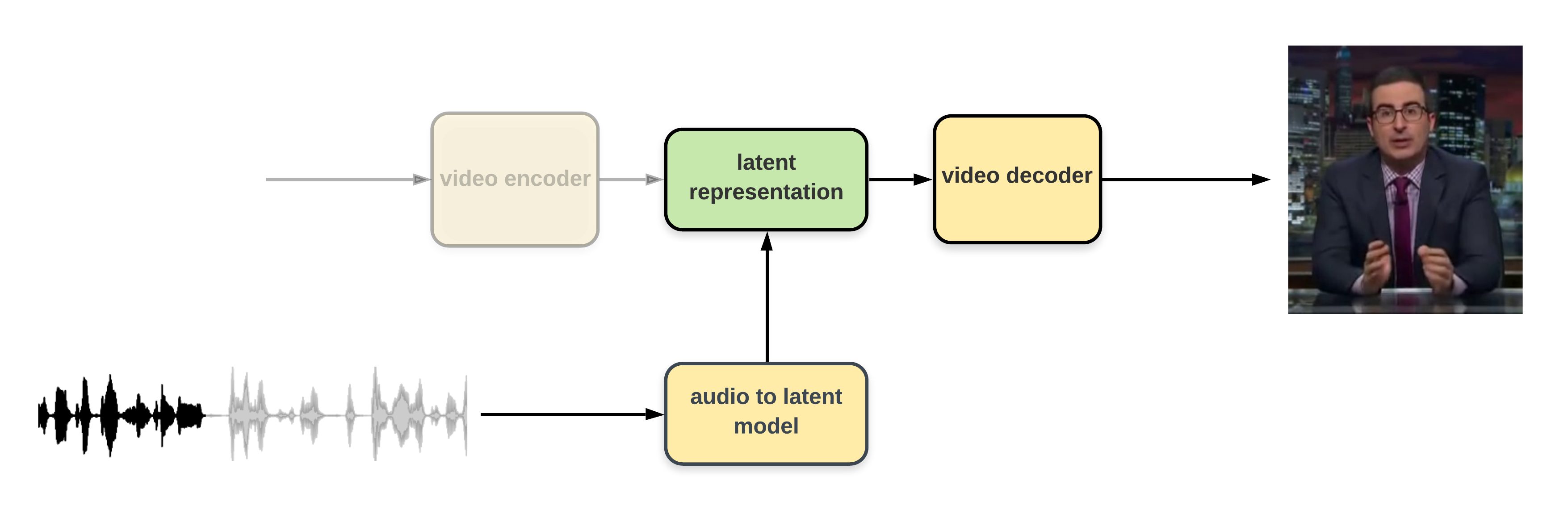
Our approach
Our discretization approach is done with a new gradient approximation technique based on attention mechanisms2,3. We also take inspiration from controllable expressiveness of text-to-speech models 4, and train our models to be able to control annotated and unannotated features of the videos. More details are available in the paper.
Related work
Speech2vid5 was the first work to use raw audio data to generate a talking head, modifying frames from a reference image or video. Synthesizing Obama6 demonstrated substantially better perceptual quality, trained on a single subject. It uses a network to predict lip shape, which is used to synthesize mouth shapes, which are recomposed into video frames using reference frames. Neural Voice Puppetry aims to be quickly adaptable to multiple subjects with a few minutes of additional video data7. It accomplishes this by using a non-subject specific 3D face model as an intermediate representation, followed by a rendering network that can be quickly tuned to produce subject-specific video. Wav2Lip8 puts emphasis on being content-neutral; using reference frames it can produce compelling lipsync results on unseen video. This also allows it to include hand movement and body movement. Speech2Video9 (not to be confused with the similarly named Speech2vid mentioned above) uses pose as its intermediate representation and a labelled pose dictionary for each subject.
Engineered intermediate representations have the problem of constraining the output space. The video rendering stage must make many assumptions from intermediate representations with low information content, in order to construct expressive motion. Small differences in facial expression can communicate highly significant expressive distinctions10, resulting in important expressive variations being represented with very little change in most intermediate representations of a face. As a result, even if those differences are actually highly correlated with learned features from the audio input, the video rendering stage must accomplish the difficult task of detecting them from a weak signal.
NWT is distinguished by its end-to-end approach that does not require domain knowledge. This would allow it to be generalized to many other audio-to-video tasks in the future.
Footnotes:
[1] NWT is an acronym of Next Week Tonight and is pronounced "newt". ↩
References:
1. van den Oord, A., Vinyals, O., and Kavukcuoglu, K. Neural discrete representation learning, 2018.↩
2. Luong, M.-T., Pham, H., and Manning, C. D. Effective approaches to attention-based neuralmachine translation, 2015.↩
3. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., and Polosukhin, I. Attention is all you need, 2017.↩
4. Hsu, W.-N., Zhang, Y., Weiss, R., Zen, H., Wu, Y., Cao, Y., and Wang, Y. Hierarchical generative modeling for controllable speech synthesis. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=rygkk305YQ. ↩
5. Chung, J. S., Jamaludin, A., and Zisserman, A. You said that? In British Machine Vision Conference, 2017. ↩
6. Suwajanakorn, S., Seitz, S. M., and Kemelmacher-Shlizerman, I. Synthesizing obama: Learning lip sync from audio. ACM Trans. Graph., 36(4), July 2017. ISSN 0730-0301. doi: 10.1145/ 3072959.3073640. URL https://doi.org/10.1145/3072959.3073640.↩
7. Thies, J., Elgharib, M. A., Tewari, A., Theobalt, C., and Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In ECCV, 2020.↩
8. Prajwal, K. R., Mukhopadhyay, R., Namboodiri, V. P., and Jawahar, C. A lip sync expert is all you need for speech to lip generation in the wild. Proceedings of the 28th ACM International Conference on Multimedia, Oct 2020. doi: 10.1145/3394171.3413532. URL http://dx.doi. org/10.1145/3394171.3413532.↩
9. Liao, M., Zhang, S., Wang, P., Zhu, H., Zuo, X., and Yang, R. Speech2video synthesis with 3d skeleton regularization and expressive body poses, 2020.↩
10. Olszanowski, M., Pochwatko, G., Kuklinski, K., Scibor-Rylski, M., Lewinski, P., and Ohme, R. K. Warsaw set of emotional facial expression pictures: a validation study of facial display photographs. Frontiers in Psychology, 5:1516, 2015. ISSN 1664-1078. doi: 10.3389/fpsyg.2014. 01516. URL https://www.frontiersin.org/article/10.3389/fpsyg.2014.01516.↩
Authors:
Acknowledgments:
The authors would like to thank Alex Krizhevsky for his mentorship and insightful discussions. The authors also thank Alyssa Kuhnert, Aydin Polat, Joe Palermo, Pippin Lee, Stephen Piron, and Vince Wong for feedback and support.
License:
This works is purely done for research purposes. We do not own the rights to the original Last Week Tonight videos.
The dataset was created using content downloaded from the official HBO Last Week
Tonight youtube
channel.
The original videos used in this project fall under the Youtube standard license.